Abstract
Reinforcement Learning (RL) has received increasing attention and adoption in real-world use cases. Most of these systems follow a train-then-fix paradigm, where trained agents do not learn while interacting with the world, until performance degrades and retraining becomes necessary. In this position paper, we argue that deploying an agent that is incapable of optimality, but receives an evaluative reward signal, is inherently a continual RL problem. We identify four sources of non-stationarity after deployment that necessitate never-ending learning, and highlight why the best deployed agents never stop adapting. We analyze successful examples of continual RL in the real world, and present the community with the advantages and measures to move away from the current train-then-fix paradigm.
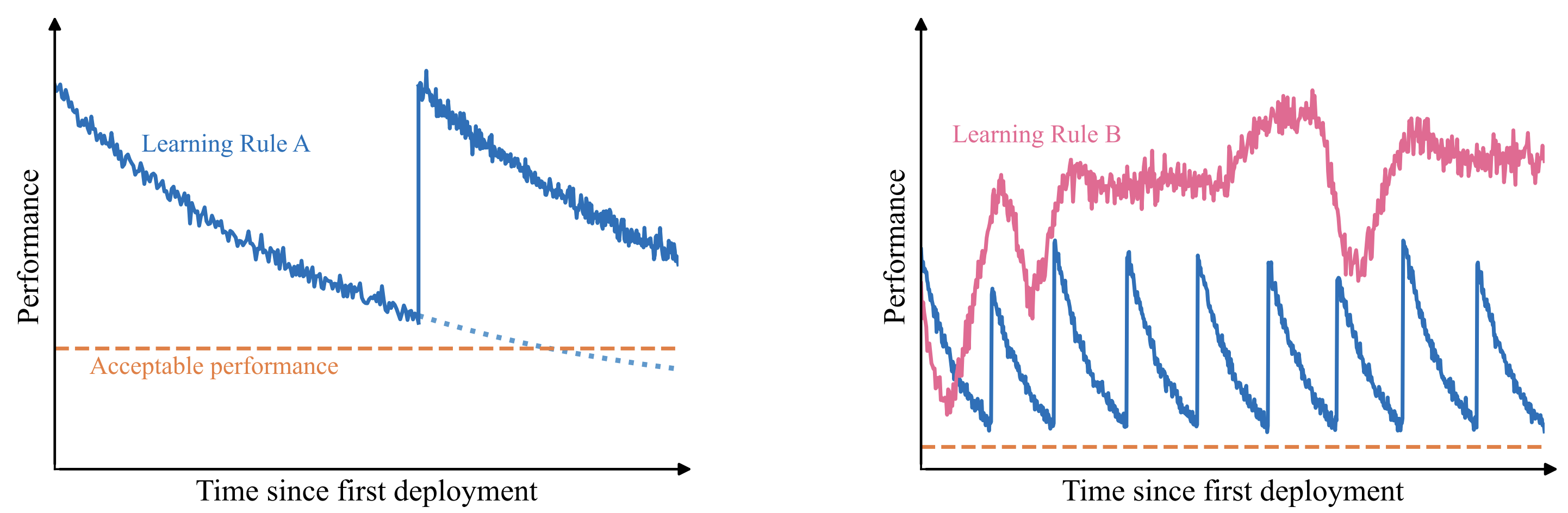
Figure 2: The train-then-fix paradigm (Learning Rule A) versus our vision for a continual learner (Learning Rule B) in measurable deployment.
Download
Citation
Behdin P., Roice K. and Mesbahi G. (2026) “Position: Deployed Reinforcement Learning should be Continual”, ICML 2026.
@inproceedings{deployedrl2026,
author = {Parnian Behdin, Kevin Roice, and Golnaz Mesbahi},
year = {2026},
title ={Position: Deployed Reinforcement Learning should be Continual},
booktitle = {International Conference on Machine Learning}}