Position: Deployed Reinforcement Learning should be Continual
ICML 2026
Paper
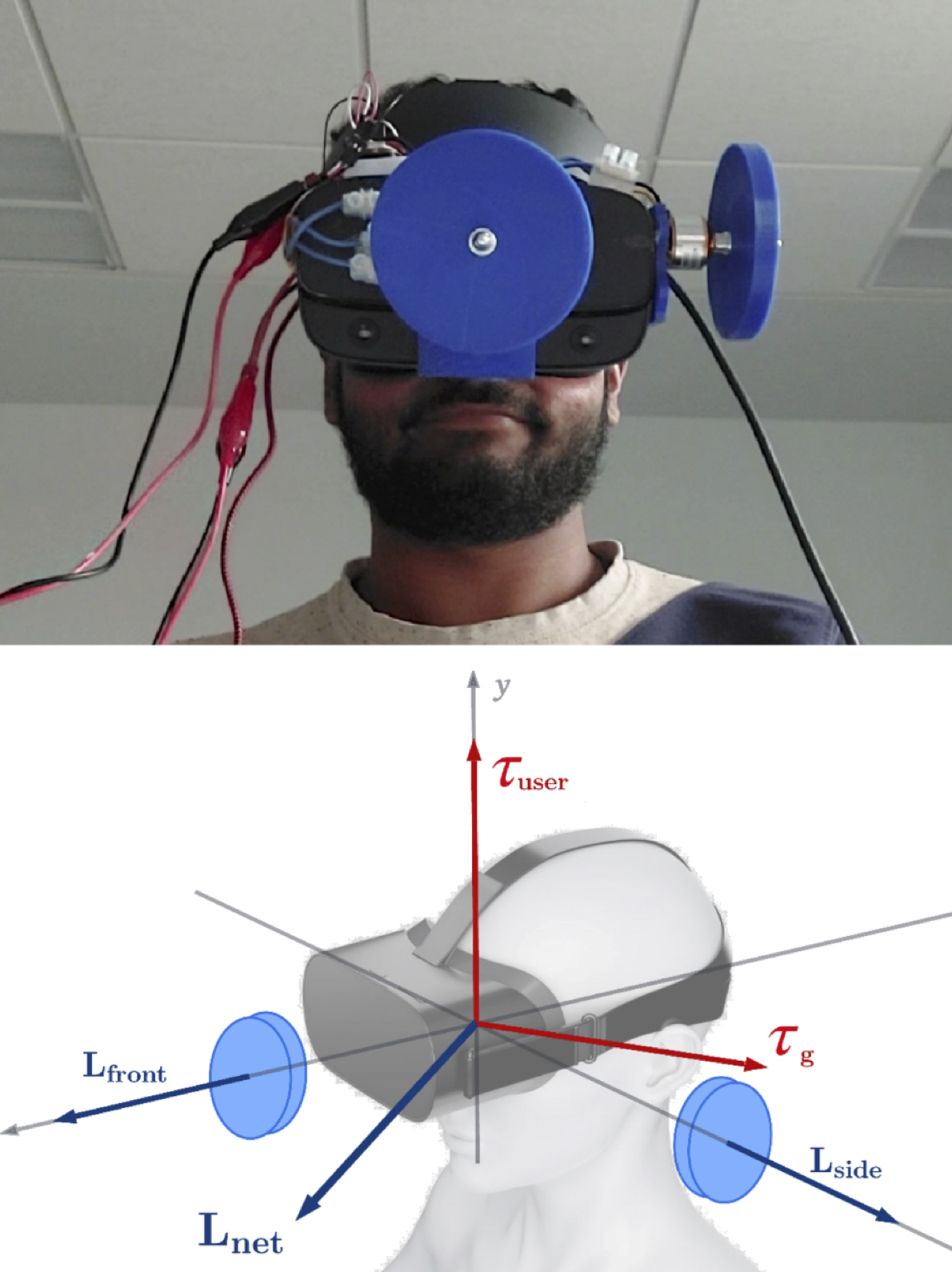
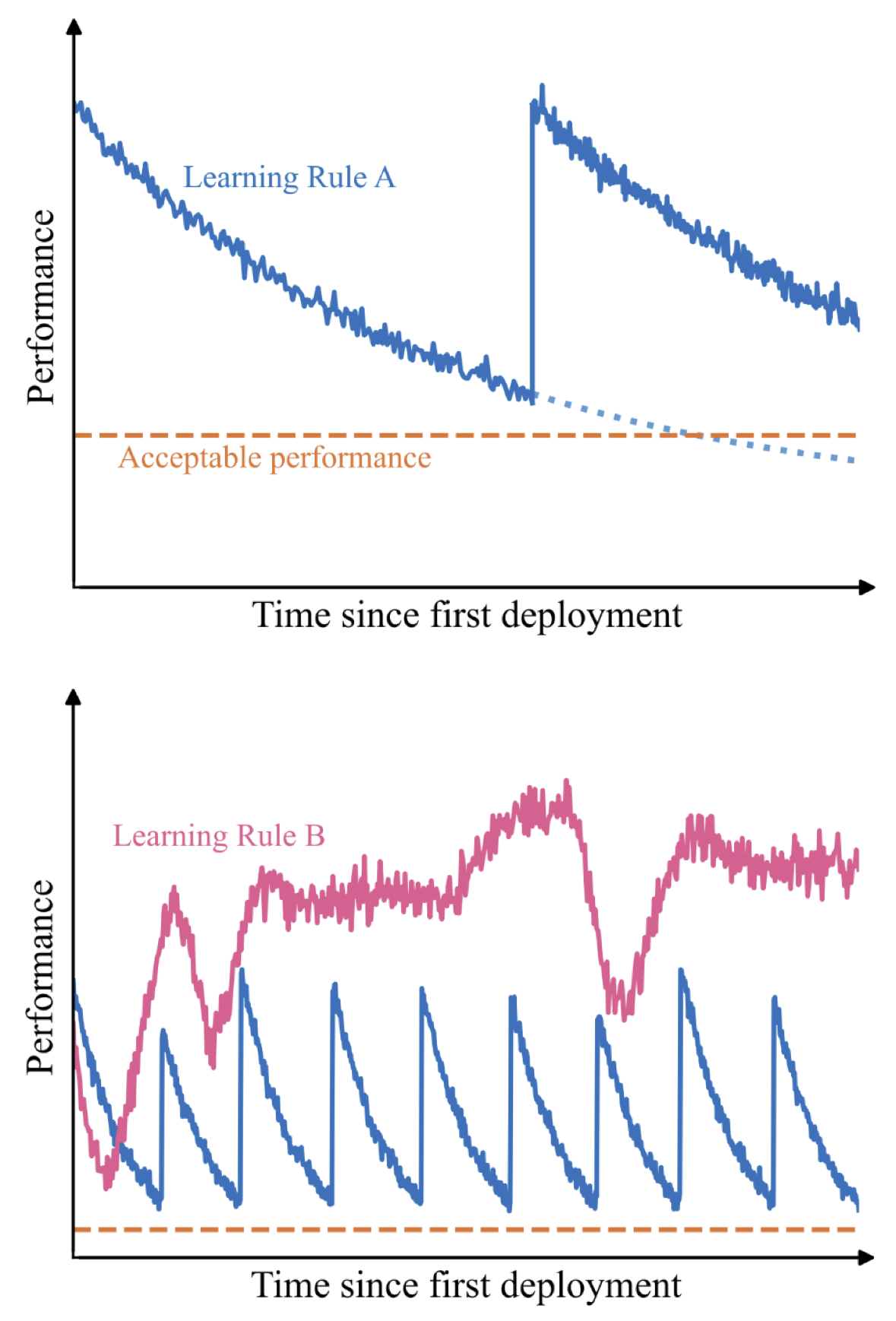
Many deployments are continual RL problems approximated as non-continual. We term these ‘measurable deployments’.
Many deployments are continual RL problems approximated as non-continual. We term these ‘measurable deployments’.
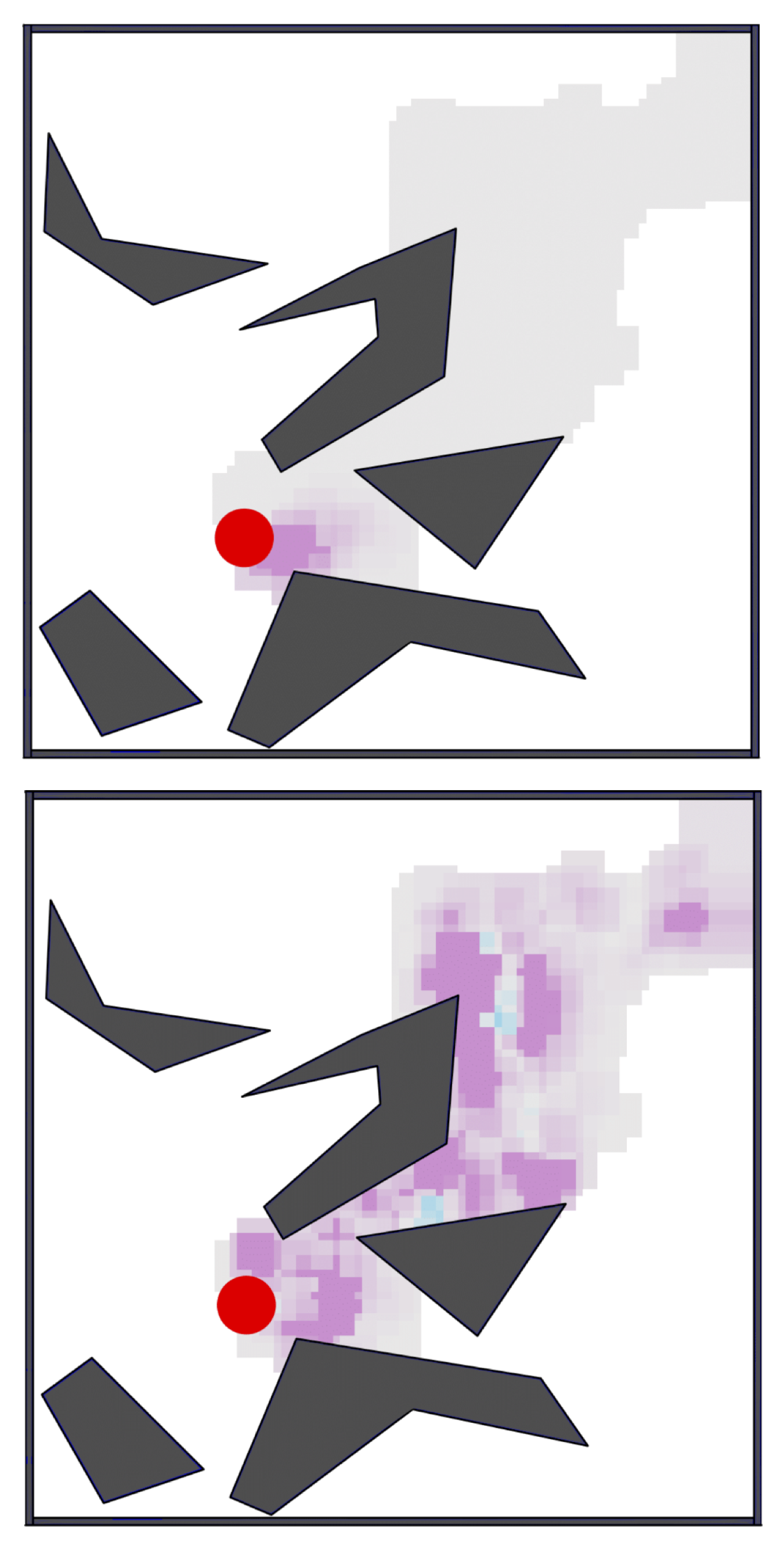
We propose a long-horizon background-planning algorithm for online RL. This used subgoal models (abstract in state & time) for faster long-term decision making & smarter value propagation.